Feed: AWS Partner Network (APN) Blog.
Author: Phil de Valence.
By Alexis Henry, Chief Technology Officer at Blu Age
By Phil de Valence, Principal Solutions Architect for Mainframe Modernization at AWS
Mainframe workloads are often tightly-coupled legacy monoliths with millions of lines of code, and customers want to modernize them for business agility.
Manually rewriting a legacy application for a cloud-native architecture requires re-engineering use cases, functions, data models, test cases, and integrations. For a typical mainframe workload with millions of lines of code, this involves large teams over long periods of time, which can be risky and cost-prohibitive.
Fortunately, Blu Age Velocity accelerates the mainframe transformation to agile serverless functions or containers. It relies on automated refactoring and preserves the investment in business functions while expediting the reliable transition to newer languages, data stores, test practices, and cloud services.
Blu Age is an AWS Partner Network (APN) Select Technology Partner that helps organizations enter the digital era by modernizing legacy systems while substantially reducing modernization costs, shortening project duration, and mitigating the risk of failure.
In this post, we’ll describe how to transform a typical mainframe CICS application to Amazon Web Services (AWS) containers and AWS Lambda functions. We’ll show you how to increase mainframe workload agility with refactoring to serverless and containers.
Customer Drivers
There are two main drivers for mainframe modernization with AWS: cost reduction and agility. Agility has many facets related to the application, underlying infrastructure, and modernization itself.
On the infrastructure agility side, customers want to go away from rigid mainframe environments in order to benefit from the AWS Cloud’s elastic compute, managed containers, managed databases, and serverless functions on a pay-as-you-go model.
They want to leave the complexity of these tightly-coupled systems in order to increase speed and adopt cloud-native architectures, DevOps best practices, automation, continuous integration and continuous deployment (CI/CD), and infrastructure as code.
On the application agility side, customers want to stay competitive by breaking down slow mainframe monoliths into leaner services and microservices, while at the same time unleashing the mainframe data.
Customers also need to facilitate polyglot architectures where development teams decide on the most suitable programming language and stack for each service.
Some customers employ large teams of COBOL developers with functional knowledge that should be preserved. Others suffer from the mainframe retirement skills gap and have to switch to more popular programming languages quickly.
Customers also require agility in the transitions. They want to choose when and how fast they execute the various transformations, and whether they’re done simultaneously or independently.
For example, a transition from COBOL to Java is not only a technical project but also requires transitioning code development personnel to the newer language and tools. It can involve retraining and new hiring.
A transition from mainframe to AWS should go at a speed which reduces complexity and minimizes risks. A transition to containers or serverless functions should be up to each service owner to decide. A transition to microservices needs business domain analysis, and consequently peeling a monolith is done gradually over time.
This post shows how Blu Age automated refactoring accelerates the customer journey to reach a company’s desired agility with cloud-native architectures and microservices. Blu Age does this by going through incremental transitions at a customer’s own pace.
Sample Mainframe COBOL Application
Let’s look at a sample application of a typical mainframe workload that we will then transform onto AWS.
This application is a COBOL application that’s accessed by users via 3270 screens defined by CICS BMS maps. It stores data in a DB2 z/OS relational database and in VSAM indexed files, using CICS Temporary Storage (TS) queues.
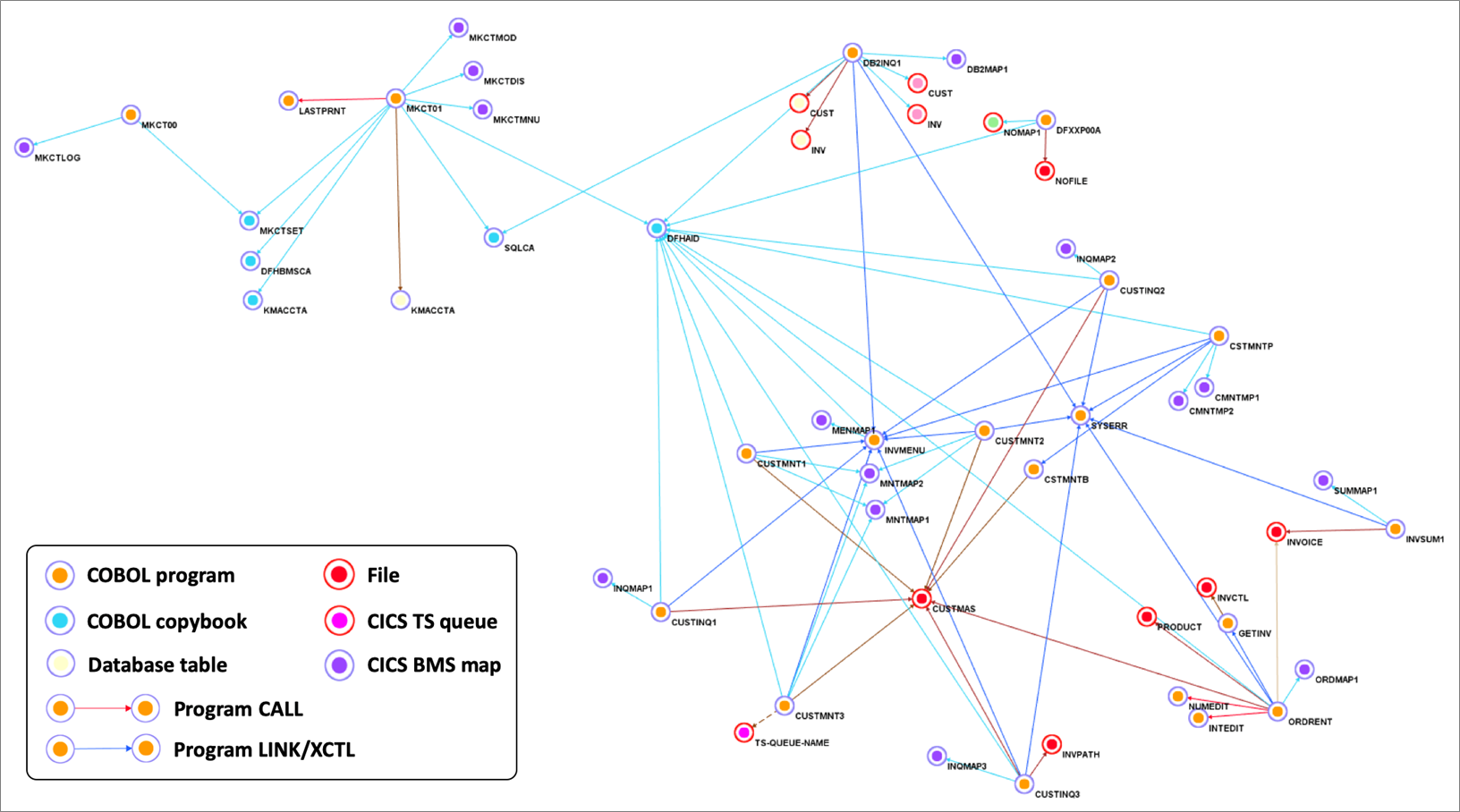
Figure 1 – Sample COBOL CICS application showing file dependencies.
We use Blu Age Analyzer to visualize the application components such as programs, copybooks, queues, and data elements.
Figure 1 above shows the Analyzer display. Each arrow represents a program call or dependency. You can see the COBOL programs using BMS maps for data entry and accessing data in DB2 database tables or VSAM files.
You can also identify the programs which are data-independent and those which access the same data file. This information helps define independent groupings that facilitate the migration into smaller services or even microservices.
This Analyzer view allows customers to identify the approach, groupings, work packages, and transitions for the automated refactoring.
In the next sections, we describe how to do the groupings and the transformation for three different target architectures: compute with Amazon Elastic Compute Cloud (Amazon EC2), containers with Amazon Elastic Kubernetes Service (Amazon EKS), and serverless functions with AWS Lambda.
Automated Refactoring to Elastic Compute
First, we transform the mainframe application to be deployed on Amazon EC2. This provides infrastructure agility with a large choice of instance types, horizontal scalability, auto scaling, some managed services, infrastructure automation, and cloud speed.
Amazon EC2 also provides some application agility with DevOps best practices, CI/CD pipeline, modern accessible data stores, and service-enabled programs.

Figure 2 – Overview of automated refactoring from mainframe to Amazon EC2.
Figure 2 above shows the automated refactoring of the mainframe application to Amazon EC2.
The DB2 tables and VSAM files are refactored to Amazon Aurora relational database. Amazon ElastiCache is used for in-memory temporary storage or for performance acceleration, and Amazon MQ takes care of the messaging communications.
Once refactored, the application becomes stateless and elastic across many duplicate Amazon EC2 instances that benefit from Auto Scaling Groups and Elastic Load Balancing (ELB). The application code stays monolithic in this first transformation.
With such monolithic transformation, all programs and dependencies are kept together. That means we create only one grouping.
Figure 3 below shows the yellow grouping that includes all application elements. Using Blu Age Analyzer, we define groupings by assigning a common tag to multiple application elements.
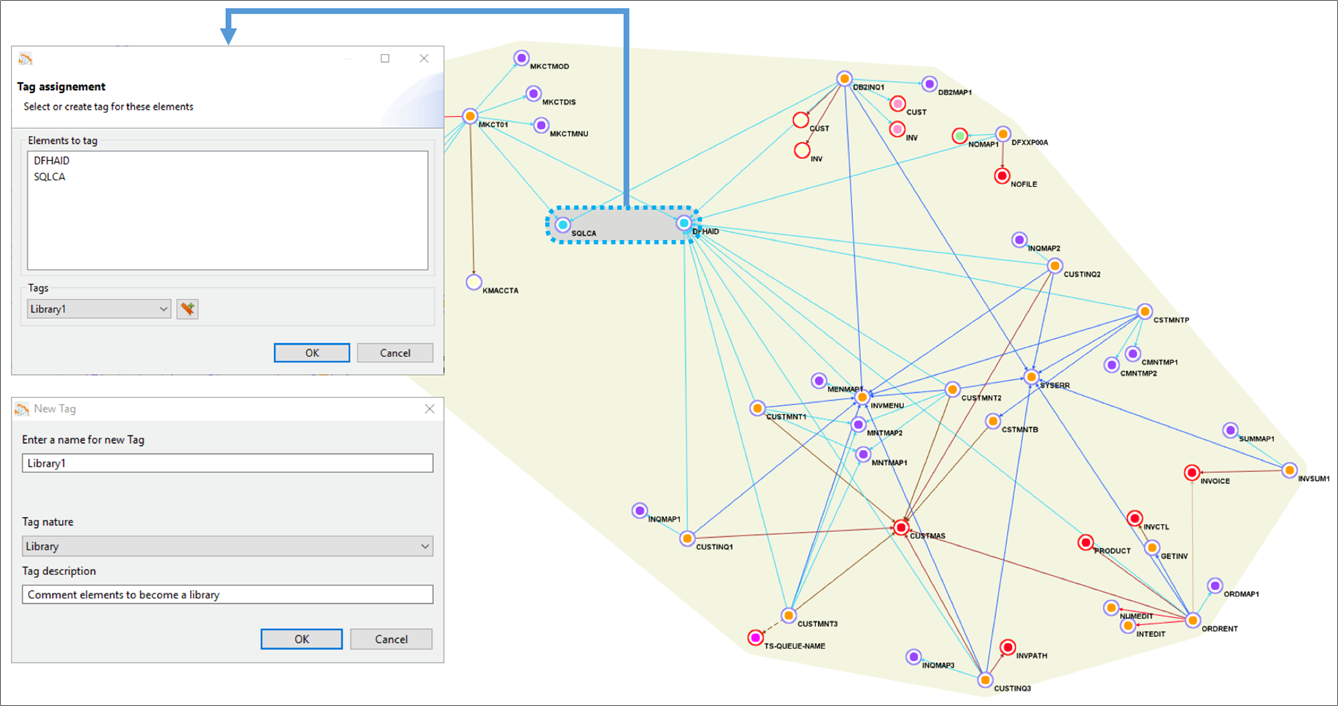
Figure 3 – Blu Age Analyzer with optional groupings for work packages and libraries.
With larger applications, it’s very likely we’d break down the larger effort by defining incremental work packages. Each work package is associated with one grouping and one tag.
Similarly, some shared programs or copybooks can be externalized and shared using a library. Each library is associated with one grouping and one tag. For example, in Figure 3 one library is created based on two programs, as shown by the grey grouping.
Ultimately, once the project is complete, all programs and work packages are deployed together within the same Amazon EC2 instances.
For each tag, we then export the corresponding application elements to Git.

Figure 4 – Blu Age Analyzer export to Git.
Figure 4 shows the COBOL programs, copybooks, DB2 Data Definition Language (DDL), and BMS map being exported to Git.
As you can see in Figure 5 below, the COBOL application elements are available in the Integrated Development Environment (IDE) for maintenance, or for new development and compilation.
Blu Age toolset allows maintaining the migrated code in either in COBOL or in Java.
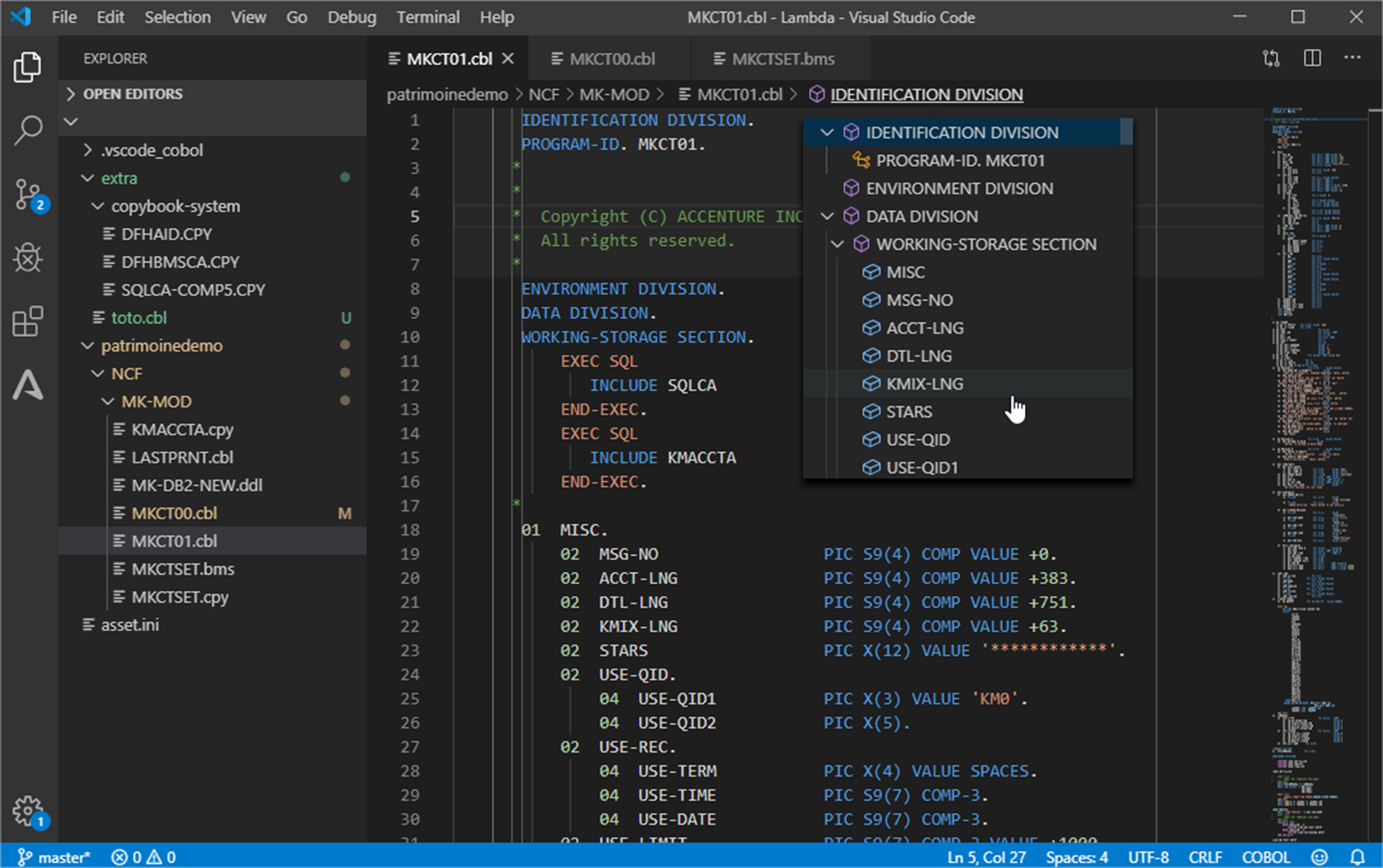
Figure 5 – Integrated Development Environment with COBOL application.
The code is recompiled and automatically packaged for the chosen target Amazon EC2 deployment.
During this packaging, the compute code is made stateless with any shared or persistent data externalized to data stores. This follows many of The Twelve-Factor App best practices that enable higher availability, scalability, and elasticity on the AWS Cloud.
In parallel, based on the code refactoring, the data from VSAM and DB2 z/OS is converted to the PostgreSQL-compatible edition of Amazon Aurora with corresponding data access queries conversions. Blu Age Velocity also generates the scripts for data conversion and migration.
Once deployed, the code and data go through unit, integration, and regression testing in order to validate functional equivalence. This is part of an automated CI/CD pipeline which also includes quality and security gates. The application is now ready for production on elastic compute.
Automated Refactoring to Containers
In this section, we increase agility by transforming the mainframe application to be deployed as different services in separate containers managed by Amazon EKS.
The application agility increases because the monolith is broken down into different services that can evolve and scale independently. Some services execute online transactions for users’ direct interactions. Some services execute batch processing. All services run in separate containers in Amazon EKS.
With such an approach, we can create microservices with both independent data stores and independent business functionalities. Read more about How to Peel Mainframe Monoliths for AWS Microservices with Blu Age.

Figure 6 – Overview of automated refactoring from mainframe to Amazon EKS.
Figure 6 shows the automated refactoring of the mainframe application to Amazon EKS. You could also use Amazon Elastic Container Service (Amazon ECS) and AWS Fargate.
The mainframe application monolith is broken down targeting different containers for various online transactions, and different containers for various batch jobs. Each service DB2 tables and VSAM files are refactored to their own independent Amazon Aurora relational database.
AWS App Mesh facilitates internal application-level communication, while Amazon API Gateway and Amazon MQ focus more on the external integration.
With the Blu Age toolset, some services can still be maintained and developed in COBOL while others can be maintained in Java, which simultaneously allows a polyglot architecture.
For the application code maintained in COBOL on AWS, Blu Age Serverless COBOL provides native integration COBOL APIs for AWS services such as Amazon Aurora, Amazon Relational Database Service (Amazon RDS), Amazon DynamoDB, Amazon ElastiCache, and Amazon Kinesis, among others.
With such refactoring, programs and dependencies are grouped into separate services. This is called service decomposition and means we create multiple groupings in Blu Age Analyzer.

Figure 7 – Blu Age Analyzer with two services groupings and one library grouping.
Figure 7 shows one service grouping in green, another service grouping in rose, and a library grouping in blue. Groupings are formalized with one tag each.
For each tag, we export the corresponding application elements to Git and open them in the IDE for compilation. We can create one Git project per tag providing independence and agility to individual service owner.

Figure 8 – COBOL program in IDE ready for compilation.
The Blu Age compiler for containers compiles the code and packages it into a Docker container image with all the necessary language runtime configuration for deployment and services communication.
The REST APIs for communication are automatically generated. The container images are automatically produced, versioned and stored into Amazon Elastic Container Registry (Amazon ECR), and the two container images are deployed onto Amazon EKS.

Figure 9 – AWS console showing the two container images created in Amazon ECR.
Figure 9 above shows the two new Docker container images referenced in Amazon ECR.
After going through data conversion and extensive testing similar to the previous section, the application is now ready for production on containers managed by Amazon EKS.
Automated Refactoring to Serverless Functions
Now, we can increase agility and cost efficiency further by targeting serverless functions in AWS Lambda.
Not only is the monolith broken down into separate services, but the services become smaller functions with no need to manage servers or containers. With Lambda, there’s no charge when the code is not running.
Not all programs are good use-cases for Lambda. Technical characteristics make Lambda better suited for short-lived lightweight stateless functions. For this reason, some services are deployed in Lambda while others are still deployed in containers or elastic compute.
For example, long-running batch processing cannot run in Lambda but they can run in containers. Online transactions or batch-specific short functions, on the other hand, can run in Lambda.
With this approach, we can create granular microservices with independent data stores and business functions.

Figure 10 – Overview of automated refactoring from mainframe to AWS Lambda.
Figure 10 shows the automated refactoring of the mainframe application to Lambda and Amazon EKS. Short-lived stateless transactions and programs are deployed in Lambda, while long-running or unsuitable programs run in Docker containers within Amazon EKS.
Amazon Simple Queue Service (SQS) is used for service calls within or across Lambda and Amazon EKS. Such architecture is similar to a cloud-native application architecture that’s much better positioned in the Cloud-Native Maturity Model.
With this refactoring, programs and dependencies are grouped into more separate services in Blu Age Analyzer.

Figure 11 – Blu Age Analyzer with two AWS Lambda groupings, on container grouping and one library grouping.
In Figure 11 above, the green grouping and yellow grouping are tagged for Lambda deployment. The rose grouping stays tagged for container deployment, while the blue grouping stays a library. Same as before, the code is exported tag after tag into Git, then opened within the IDE for compilation.
The compilation and deployment for Lambda does not create a container image, but it creates compiled code ready to be deployed on Blu Age Serverless COBOL layer for Lambda.
Here’s the Serverless COBOL layer added to the deployed functions.
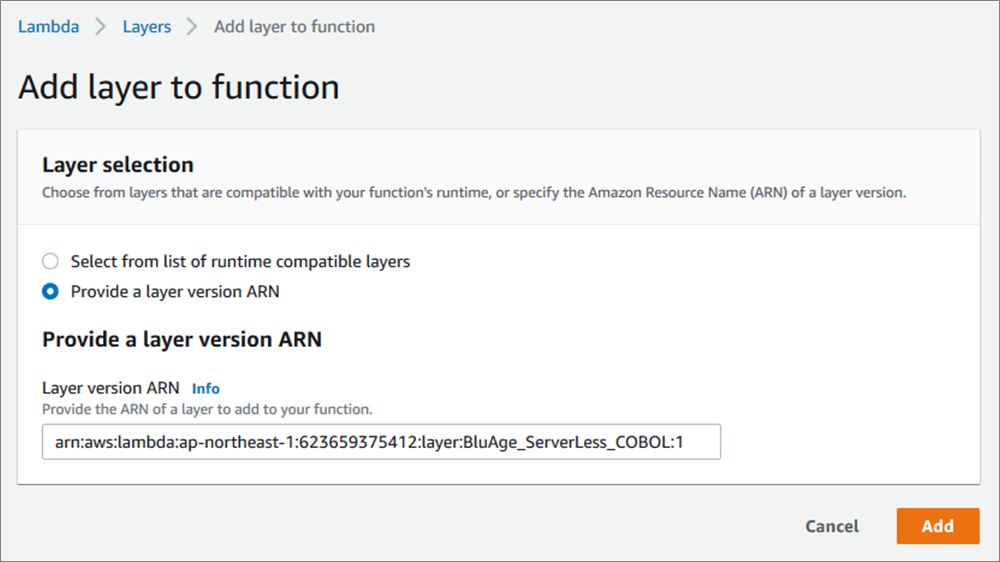
Figure 12 – Blu Age Serverless COBOL layer added to AWS Lambda function.
Now, here’s the two new Lambda functions created once the compiled code is deployed.

Figure 13 – AWS console showing the two AWS Lambda functions created.
After data conversion and thorough testing similar to the previous sections, the application is now ready for production on serverless functions and containers.
With business logic in Lambda functions, this logic can be invoked from many sources (REST APIs, messaging, object store, streams, databases) for innovations.
Incremental Transitions
Automated refactoring allows customers to accelerate modernization and minimize project risks on many dimensions.
On one side, the extensive automation for the full software stack conversion including code, data formats, dependencies provides functional equivalence preserving core business logic.
On the other side, the solution provides incremental transitions and accelerators tailored to the customer constraints and objectives:
- Incremental transition from mainframe to AWS: As shown with Blu Age Analyzer, a large application migration is piece-mealed into small work packages with coherent programs and data elements. The migration does not have to be a big bang, and it can be executed incrementally over time.
. - Incremental transition from COBOL to Java: Blu Age compilers and toolset supports maintaining the application code either in the original COBOL or Java.
.
All the deployment options described previously can be maintained similarly in COBOL or in Java and co-exist. That means you can choose to keep developing in COBOL if appropriate, and decide to start developing in Java when convenient facilitating knowledge transfer between developers.
. - Incremental transition from elastic compute, to containers, to functions: Some customers prefer starting with elastic compute, while others prefer jumping straight to containers or serverless functions. Blu Age toolset has the flexibility to switch from one target to the other following the customer specific needs.
. - Incremental transition from monolith to services and microservices: Peeling a large monolith is a long process, and the monolith can be kept and deployed on the various compute targets. When time comes, services or microservices are identified in Blu Age Analyzer, and then extracted and deployed on elastic compute, containers, or serverless functions.
From a timeline perspective, the incremental transition from mainframe to AWS is a short-term project with achievable return on investment, as shown on Figure 14.

Figure 14 – Mainframe to AWS transition timeline.
We recommend starting with a hands-on Proof-of-Concept (PoC) with customers’ real code. It’s the only way to prove the technical viability and show the outcome quality within 6 weeks.
Then, you can define work packages and incrementally refactor the mainframe application to AWS targeting elastic compute, containers, or serverless functions.
The full refactoring of a mainframe workload onto AWS can be completed in a year. As soon as services are refactored and in production on AWS, new integrations and innovations become possible for analytics, mobile, voice, machine learning (ML), or Internet of Things (IoT) use cases.
Summary
Blu Age mainframe automated refactoring provides the speed and flexibility to meet the agility needs of customers. It leverages the AWS quality of service for high security, high availability, elasticity, and rich system management to meet or exceed the mainframe workloads requirements.
While accelerating modernization, Blu Age toolset allows incremental transitions adapting to customers priorities. It accelerates mainframe modernization to containers or serverless functions
Blu Age also gives the option to keep developing in COBOL or transition smoothly to Java. It facilitates the identification and extraction of microservices.
For more details, visit the Serverless COBOL page and contact Blu Age to learn more.
.
.
Blu Age – APN Partner Spotlight
Blu Age is an APN Select Technology Partner that helps organizations enter the digital era by modernizing legacy systems while substantially reducing modernization costs, shortening project duration, and mitigating the risk of failure.
Contact Blu Age | Solution Overview | AWS Marketplace
*Already worked with Blu Age? Rate this Partner
*To review an APN Partner, you must be an AWS customer that has worked with them directly on a project.












 Pedro Completo Bento is a senior big data engineer working at Siemens CDC. He holds a Master in Computer Science from the Instituto Superior Técnico in Lisbon. He started his career as a full-stack developer, specializing later on big data challenges. Working with AWS, he builds highly reliable, performant and scalable systems on the cloud, while keeping the costs at bay. In his free time, he enjoys to play boardgames with his friends.
Pedro Completo Bento is a senior big data engineer working at Siemens CDC. He holds a Master in Computer Science from the Instituto Superior Técnico in Lisbon. He started his career as a full-stack developer, specializing later on big data challenges. Working with AWS, he builds highly reliable, performant and scalable systems on the cloud, while keeping the costs at bay. In his free time, he enjoys to play boardgames with his friends. Arturo Bayo is a big data consultant at Amazon Web Services. He promotes a data-driven culture in enterprise customers around EMEA, providing specialized guidance on business intelligence and data lake projects while working with AWS customers and partners to build innovative solutions around data and analytics.
Arturo Bayo is a big data consultant at Amazon Web Services. He promotes a data-driven culture in enterprise customers around EMEA, providing specialized guidance on business intelligence and data lake projects while working with AWS customers and partners to build innovative solutions around data and analytics.


 Steffen Hausmann is a Specialist Solutions Architect for Analytics at AWS. He works with customers around the globe to design and build streaming architectures so that they can get value from analyzing their streaming data. He holds a doctorate degree in computer science from the University of Munich and in his free time, he tries to lure his daughters into tech with cute stickers he collects at conferences. You can follow his ruthless attempts on Twitter (@sthmmm).
Steffen Hausmann is a Specialist Solutions Architect for Analytics at AWS. He works with customers around the globe to design and build streaming architectures so that they can get value from analyzing their streaming data. He holds a doctorate degree in computer science from the University of Munich and in his free time, he tries to lure his daughters into tech with cute stickers he collects at conferences. You can follow his ruthless attempts on Twitter (@sthmmm).






































 platform. In
platform. In 