Feed: AWS Compute Blog.
Author: Eric Johnson.
Over the last year, I have been talking about “storage first” serverless patterns. With these patterns, data is stored persistently before any business logic is applied. The advantage of this pattern is increased application resiliency. By persisting the data before processing, the original data is still available, if or when errors occur.

Common pattern for serverless API backend
Using Amazon API Gateway as a proxy to an AWS Lambda function is a common pattern in serverless applications. The Lambda function handles the business logic and communicates with other AWS or third-party services to route, modify, or store the processed data. One option is to place the data in an Amazon Simple Queue Service (SQS) queue for processing downstream. In this pattern, the developer is responsible for handling errors and retry logic within the Lambda function code.
The storage first pattern flips this around. It uses native error handling with retry logic or dead-letter queues (DLQ) at the SQS layer before any code is run. By directly integrating API Gateway to SQS, developers can increase application reliability while reducing lines of code.

Storage first pattern for serverless API backend
Previously, direct integrations require REST APIs with transformation templates written in Velocity Template Language (VTL). However, developers tell us they would like to integrate directly with services in a simpler way without using VTL. As a result, HTTP APIs now offers the ability to directly integrate with five AWS services without needing a transformation template or code layer.
The first five service integrations
This release of HTTP APIs direct integrations includes Amazon EventBridge, Amazon Kinesis Data Streams, Simple Queue Service (SQS), AWS System Manager’s AppConfig, and AWS Step Functions. With these new integrations, customers can create APIs and webhooks for their business logic hosted in these AWS services. They can also take advantage of HTTP APIs features like authorizers, throttling, and enhanced observability for securing and monitoring these applications.
Amazon EventBridge

HTTP APIs service integration with Amazon EventBridge
The HTTP APIs direct integration for EventBridge uses the PutEvents API to enable client applications to place events on an EventBridge bus. Once the events are on the bus, EventBridge routes the event to specific targets based upon EventBridge filtering rules.
This integration is a storage first pattern because data is written to the bus before any routing or logic is applied. If the downstream target service has issues, then EventBridge implements a retry strategy with incremental back-off for up to 24 hours. Additionally, the integration helps developers reduce code by filtering events at the bus. It routes to downstream targets without the need for a Lambda function as a transport layer.
Use this direct integration when:
- Different tasks are required based upon incoming event details
- Only data ingestion is required
- Payload size is less than 256 kb
- Expected requests per second are less than the Region quotas.
Amazon Kinesis Data Streams

HTTP APIs service integration with Amazon Kinesis Data Streams
The HTTP APIs direct integration for Kinesis Data Streams offers the PutRecord integration action, enabling client applications to place events on a Kinesis data stream. Kinesis Data Streams are designed to handle up to 1,000 writes per second per shard, with payloads up to 1 mb in size. Developers can increase throughput by increasing the number of shards in the data stream. You can route the incoming data to targets like an Amazon S3 bucket as part of a data lake or a Kinesis data analytics application for real-time analytics.
This integration is a storage first option because data is stored on the stream for up to seven days until it is processed and routed elsewhere. When processing stream events with a Lambda function, errors are handled at the Lambda layer through a configurable error handling strategy.
Use this direct integration when:
- Ingesting large amounts of data
- Ingesting large payload sizes
- Order is important
- Routing the same data to multiple targets
Amazon SQS

HTTP APIs service integration with Amazon SQS
The HTTP APIs direct integration for Amazon SQS offers the SendMessage, ReceiveMessage, DeleteMessage, and PurgeQueue integration actions. This integration differs from the EventBridge and Kinesis integrations in that data flows both ways. Events can be created, read, and deleted from the SQS queue via REST calls through the HTTP API endpoint. Additionally, a full purge of the queue can be managed using the PurgeQueue action.
This pattern is a storage first pattern because the data remains on the queue for four days by default (configurable to 14 days), unless it is processed and removed. When the Lambda service polls the queue, the messages that are returned are hidden in the queue for a set amount of time. Once the calling service has processed these messages, it uses the DeleteMessage API to remove the messages permanently.
When triggering a Lambda function with an SQS queue, the Lambda service manages this process internally. However, HTTP APIs direct integration with SQS enables developers to move this process to client applications without the need for a Lambda function as a transport layer.
Use this direct integration when:
- Data must be received as well as sent to the service
- Downstream services need reduced concurrency
- The queue requires custom management
- Order is important (FIFO queues)
AWS AppConfig

HTTP APIs service integration with AWS Systems Manager AppConfig
The HTTP APIs direct integration for AWS AppConfig offers the GetConfiguration integration action and allows applications to check for application configuration updates. By exposing the systems parameter API through an HTTP APIs endpoint, developers can automate configuration changes for their applications. While this integration is not considered a storage first integration, it does enable direct communication from external services to AppConfig without the need for a Lambda function as a transport layer.
Use this direct integration when:
- Access to AWS AppConfig is required.
- Managing application configurations.
AWS Step Functions

HTTP APIs service integration with AWS Step Functions
The HTTP APIs direct integration for Step Functions offers the StartExecution and StopExecution integration actions. These actions allow for programmatic control of a Step Functions state machine via an API. When starting a Step Functions workflow, JSON data is passed in the request and mapped to the state machine. Error messages are also mapped to the state machine when stopping the execution.
This pattern provides a storage first integration because Step Functions maintains a persistent state during the life of the orchestrated workflow. Step Functions also supports service integrations that allow the workflows to send and receive data without needing a Lambda function as a transport layer.
Use this direct integration when:
- Orchestrating multiple actions.
- Order of action is required.
Building HTTP APIs direct integrations
HTTP APIs service integrations can be built using the AWS CLI, AWS SAM, or through the API Gateway console. The console walks through contextual choices to help you understand what is required for each integration. Each of the integrations also includes an Advanced section to provide additional information for the integration.

Creating an HTTP APIs service integration
Once you build an integration, you can export it as an OpenAPI template that can be used with infrastructure as code (IaC) tools like AWS SAM. The exported template can also include the API Gateway extensions that define the specific integration information.

Exporting the HTTP APIs configuration to OpenAPI
OpenAPI template
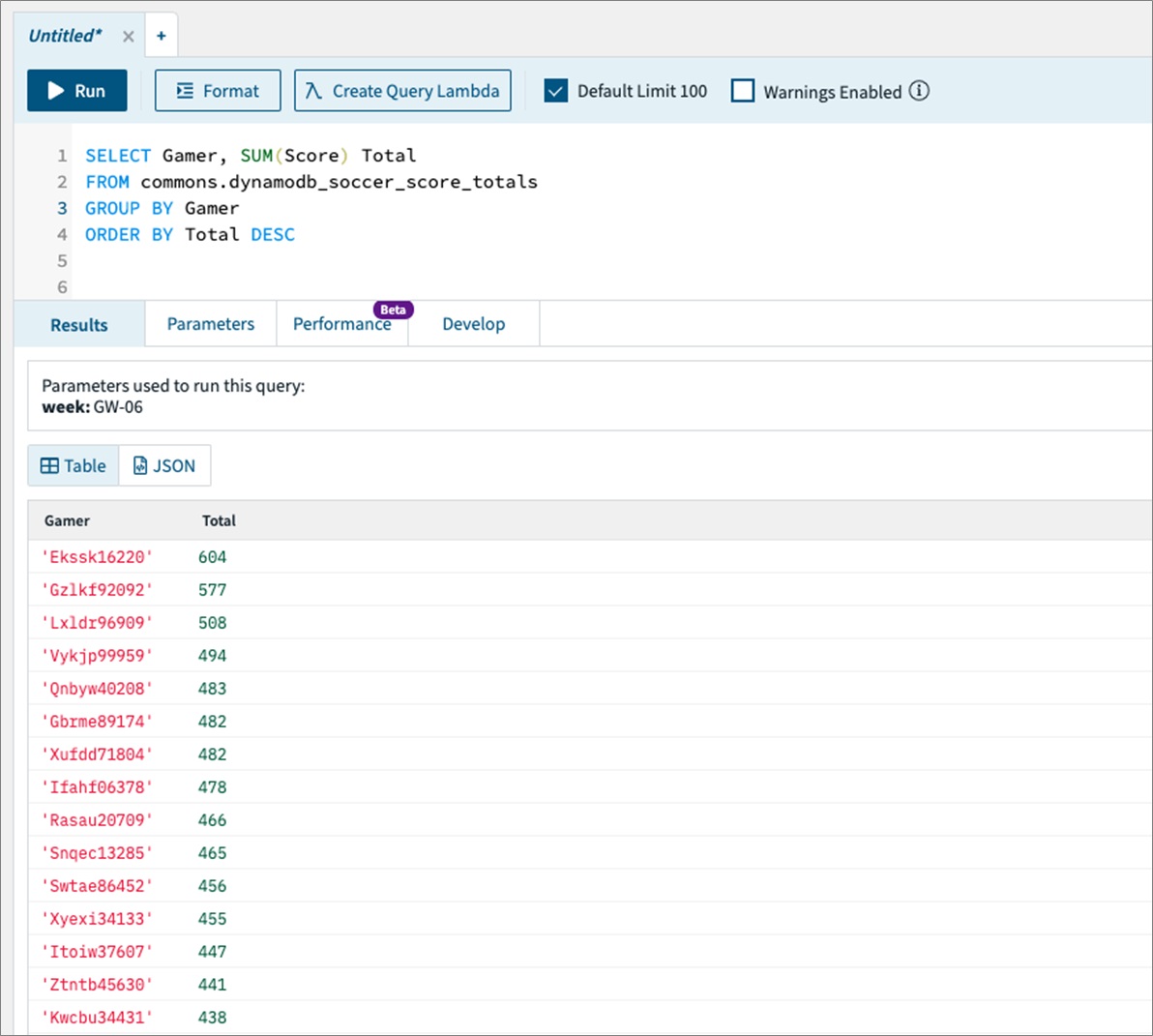
An example of a direct integration from HTTP APIs to SQS is located in the Sessions With SAM repository. This example includes the following architecture:

AWS SAM template resource architecture
The AWS SAM template creates the HTTP APIs, SQS queue, Lambda function, and both Identity and Access Management (IAM) roles required. This is all generated in 58 lines of code and looks like this:
AWSTemplateFormatVersion: '2010-09-09'
Transform: AWS::Serverless-2016-10-31
Description: HTTP API direct integrations
Resources:
MyQueue:
Type: AWS::SQS::Queue
MyHttpApi:
Type: AWS::Serverless::HttpApi
Properties:
DefinitionBody:
'Fn::Transform':
Name: 'AWS::Include'
Parameters:
Location: './api.yaml'
MyHttpApiRole:
Type: "AWS::IAM::Role"
Properties:
AssumeRolePolicyDocument:
Version: "2012-10-17"
Statement:
- Effect: "Allow"
Principal:
Service: "apigateway.amazonaws.com"
Action:
- "sts:AssumeRole"
Policies:
- PolicyName: ApiDirectWriteToSQS
PolicyDocument:
Version: '2012-10-17'
Statement:
Action:
- sqs:SendMessage
Effect: Allow
Resource:
- !GetAtt MyQueue.Arn
MyTriggeredLambda:
Type: AWS::Serverless::Function
Properties:
CodeUri: src/
Handler: app.lambdaHandler
Runtime: nodejs12.x
Policies:
- SQSPollerPolicy:
QueueName: !GetAtt MyQueue.QueueName
Events:
SQSTrigger:
Type: SQS
Properties:
Queue: !GetAtt MyQueue.Arn
Outputs:
ApiEndpoint:
Description: "HTTP API endpoint URL"
Value: !Sub "https://${MyHttpApi}.execute-api.${AWS::Region}.amazonaws.com"
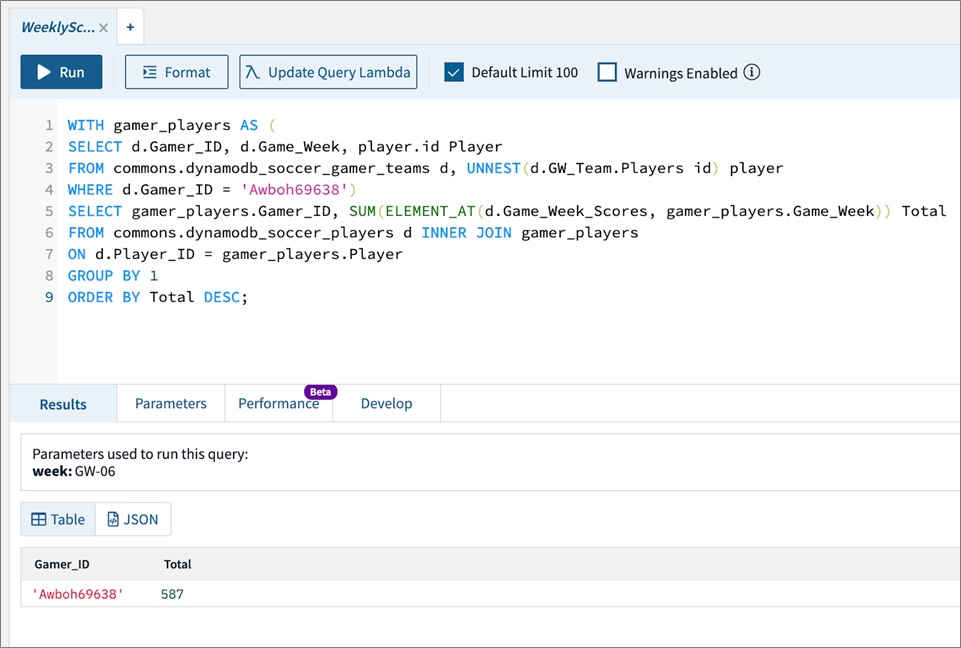
The OpenAPI template handles the route definitions for the HTTP API configuration and configures the service integration. The template looks like this:
openapi: "3.0.1"
info:
title: "my-sqs-api"
paths:
/:
post:
responses:
default:
description: "Default response for POST /"
x-amazon-apigateway-integration:
integrationSubtype: "SQS-SendMessage"
credentials:
Fn::GetAtt: [MyHttpApiRole, Arn]
requestParameters:
MessageBody: "$request.body.MessageBody"
QueueUrl:
Ref: MyQueue
payloadFormatVersion: "1.0"
type: "aws_proxy”
connectionType: "INTERNET"
x-amazon-apigateway-importexport-version: "1.0"
Because the OpenAPI template is included in the AWS SAM template via a transform, the API Gateway integration can reference the roles and services created within the AWS SAM template.
Conclusion
This post covers the concept of storage first integration patterns and how the new HTTP APIs direct integrations can help. I cover the five current integrations and possible use cases for each. Additionally, I demonstrate how to use AWS SAM to build and manage the integrated applications using infrastructure as code.
Using the storage first pattern with direct integrations can help developers build serverless applications that are more durable with fewer lines of code. A Lambda function is no longer required to transport data from the API endpoint to the desired service. Instead, use Lambda function invocations for differentiating business logic.
To learn more join us for the HTTP API service integrations session of Sessions With SAM!
#ServerlessForEveryone




.png "Picture1-(1).png")
.png "Picture1-(2).png")




























 Viral Shah is a Data Lab Architect with Amazon Web Services. Viral helps our customers architect and build data and analytics prototypes in just four days in the
Viral Shah is a Data Lab Architect with Amazon Web Services. Viral helps our customers architect and build data and analytics prototypes in just four days in the  Persistence Memory Modules. Not only have we fixed an issue with exploiting the full capacity of all installed modules on the system, Hazelcast IMDG now provides performance tuning options to get the speed of Optane
Persistence Memory Modules. Not only have we fixed an issue with exploiting the full capacity of all installed modules on the system, Hazelcast IMDG now provides performance tuning options to get the speed of Optane









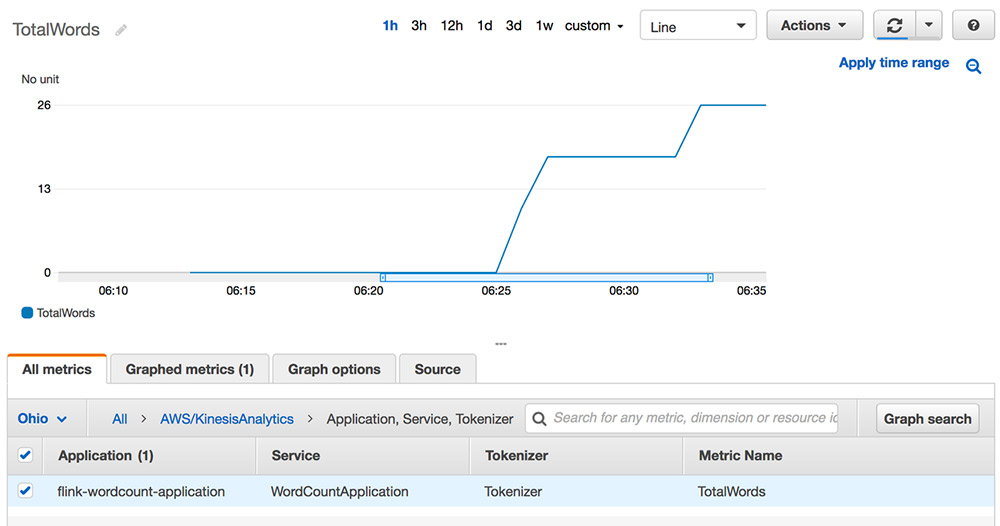

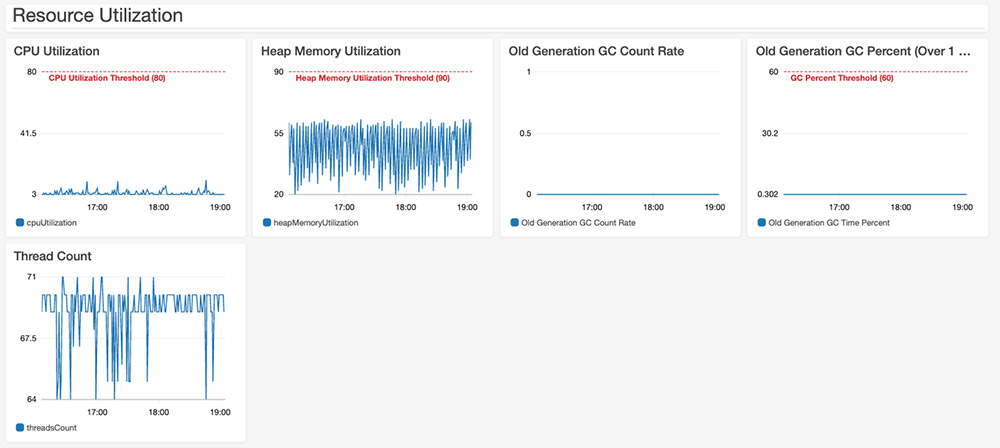
 Karthi Thyagarajan is a Principal Solutions Architect on the Amazon Kinesis team.
Karthi Thyagarajan is a Principal Solutions Architect on the Amazon Kinesis team. Deepthi Mohan is a Sr. TPM on the Amazon Kinesis Data Analytics team.
Deepthi Mohan is a Sr. TPM on the Amazon Kinesis Data Analytics team.













